High-level Design
We will follow the advice we’ve given in this course and will try to scope out a high-level design proposal before going into more details.
Looks like we will have several types of front-end for submitting text articles. There is a website and a mobile app, possibly with different versions for the different mobile operating systems. All these front-ends will have to be served by some piece of code, which runs the text summarization library.
In such cases it makes most sense to have one service sitting in the back-end serving requests from all possible front-end clients instead of having multiple services, one for each type of client. This back-end service will contain the code, which parses text articles and produces summaries for them by using the existing library.
Who talks to whom?
Now comes the question of how will the front-end clients talk to this back-end service. One possibility is to just have a RESTful API exposed by the summarization service, which all the front-end clients send HTTP requests to. This is a rather simple solution but it can have a few problems. We will look at these problems and discuss a better approach when we start discussing the scalability issues of our architecture.
Naturally, the responses will also have to get back to the front-end clients somehow. The way this is going to happen will also be discussed in more details when we get to the low-level design. For our high-level design it’s enough to outline the main actors and the communication channels between them.
Where do we store things?
Another thing to consider is the storage of the data. Our interviewer said that we have to store the incoming text articles and the generated summaries. In order to decide what storage solution is good we should probably know the expected size of the text articles and the summaries. Hm, seems like we didn’t ask this question initially. It’s ok to come up with additional questions in the process of building our design. So, let’s ask that.
The interviewer replies:
"We will limit the size of the text articles to be no more than 100 KB, this is our target at the moment. The summaries are meant to be quite smaller than that - no more than 1KB in size."
Considering that we expect 1 million requests per month, the maximum total size of all text articles received should be 1 mln * 100 KB or 100 GB per month. For one year we could accumulate up to 1.2 TB of data. The number of records won’t be very high though - 12 million at most per year. It seems reasonable to store the incoming text articles and the summaries in a relational database. Of course it is also fine to consider a NoSql solution or even a storage solution like S3 at least for the text articles. The choice partially depends on the goals of the company. Let’s ask the interviewer - how will this data be used? The answer:
"We will use the stored data to analyze the accuracy of our algorithms and also for some statistical goals. We will also want to show to our customers a history of their requests and the summaries that they received."
With this in mind it’s probably a good idea to use either a RDBMS or a NoSql solution. Either should work out well for us considering that they will be used to just store the data and fetch it by user.
Let’s try to draw a diagram of the design outlined so far:
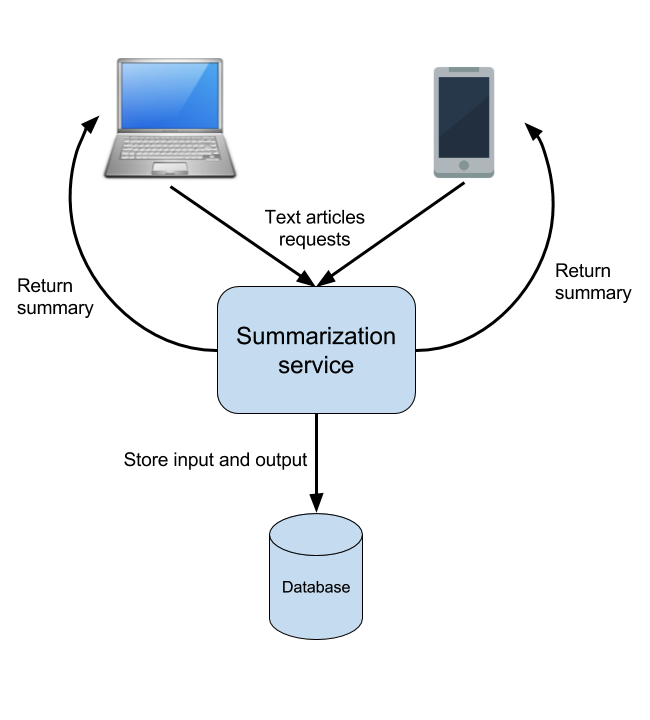
It shows the main components of the design and the sequence of actions that are needed to handle one request. There are many important details mainly related to scalability that are not described in this diagram and we will discuss them next. However, this is a good start no matter how simple it looks.